Postgres Query Insights
Query Insights собирает телеметрию по каждому оператору из вашего Managed Postgres и ранжирует каждый шаблон запроса по степени влияния, чтобы вы могли перейти от «p99 постепенно растёт» к «этот шаблон сбрасывает данные на диск», не покидая облачную консоль.
Данные поступают из pg_stat_ch,
расширения Postgres с открытым исходным кодом, которое передаёт в
ClickHouse Cloud счётчики по каждому оператору. Телеметрия нормализуется внутри
Postgres до того, как покинет базу данных: литералы удаляются и заменяются
плейсхолдерами, поэтому точные значения из ваших запросов никогда не попадают в поток телеметрии.
Откройте Query insights
Откройте свой экземпляр Managed Postgres в облачной консоли и нажмите Query insights на левой боковой панели. Страница разделена на четыре блока в том порядке, в котором вы обычно будете их использовать:
- Раздел Overview, в котором вся проверка состояния базы данных помещается на одном экране.
- Таблица Slow patterns, в которой собраны все шаблоны запросов, выполнявшихся в вашей базе данных, с сортировкой по интересующему вас признаку.
- Панель Recent queries, где отдельные выполнения перечислены в обратном хронологическом порядке.
- Выдвижная панель с деталями, в которой собраны все счётчики для одного шаблона.
Используйте переключатель Time period вверху, чтобы выбрать последние 15 минут, час, день, неделю или месяц. Размер бакета агрегации подстраивается автоматически: бакеты по 1 минуте для последних 15 минут или часа, по 5 минут для последнего дня и по 1 часу для последней недели или месяца, чтобы графики оставались отзывчивыми.
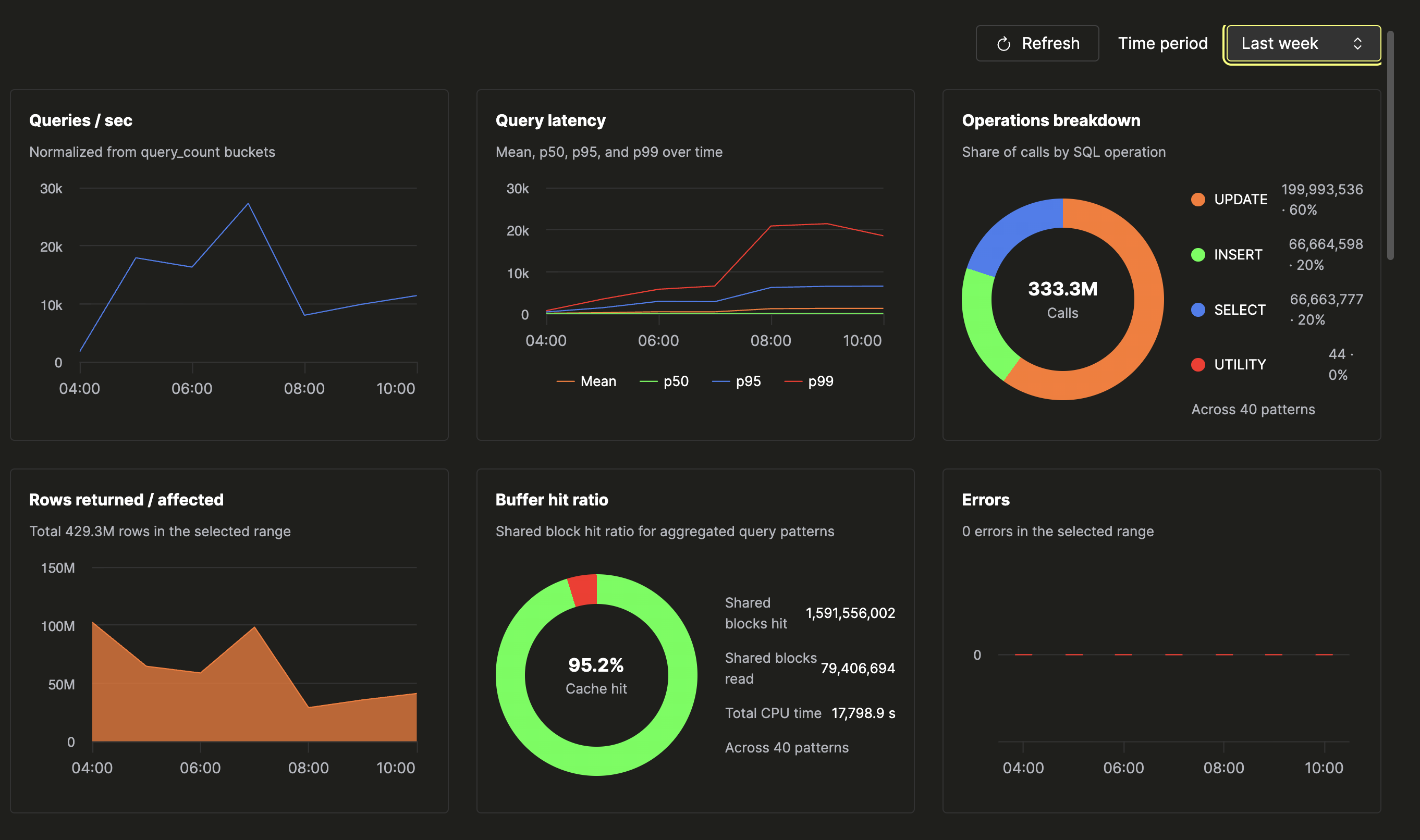
Обзор
Обзор представляет собой сетку 3×2 из шести панелей:
| Панель | Что она показывает |
|---|---|
| Запросы / сек | Объём запросов, приведённый к частоте за выбранный интервал. |
| Задержка запросов | Среднее, p50, p95 и p99 на одном графике, чтобы видеть, когда хвост распределения начинает заметно расходиться с медианой. |
| Разбивка операций | Кольцевая диаграмма, показывающая, из какого соотношения SELECT, INSERT, UPDATE и других операций фактически состоит ваша рабочая нагрузка. |
| Возвращённые / затронутые строки | Общее количество строк, которое рабочая нагрузка вернула или затронула за выбранный интервал. |
| Коэффициент попаданий в буфер | Кольцевая диаграмма соотношения попаданий в общие блоки и чтений общих блоков; в легенде указано общее время CPU. |
| Ошибки | Общее количество ошибок с разбивкой по времени. |
По одному экрану можно понять, в каком состоянии база данных. Для здорового экземпляра характерна типичная картина: коэффициент попаданий в буфер — выше 90%, объём запросов меняется вместе с трафиком приложения, уровень ошибок остаётся ровным или нулевым, а процентильные задержки идут близко друг к другу.
Медленные паттерны
Если в обзоре видны проблемы, расследование стоит начать с таблицы шаблонов запросов. По одной строке на каждый нормализованный шаблон запроса: литералы из него удалены, поэтому все выполнения одного и того же оператора сводятся к одной и той же строке.
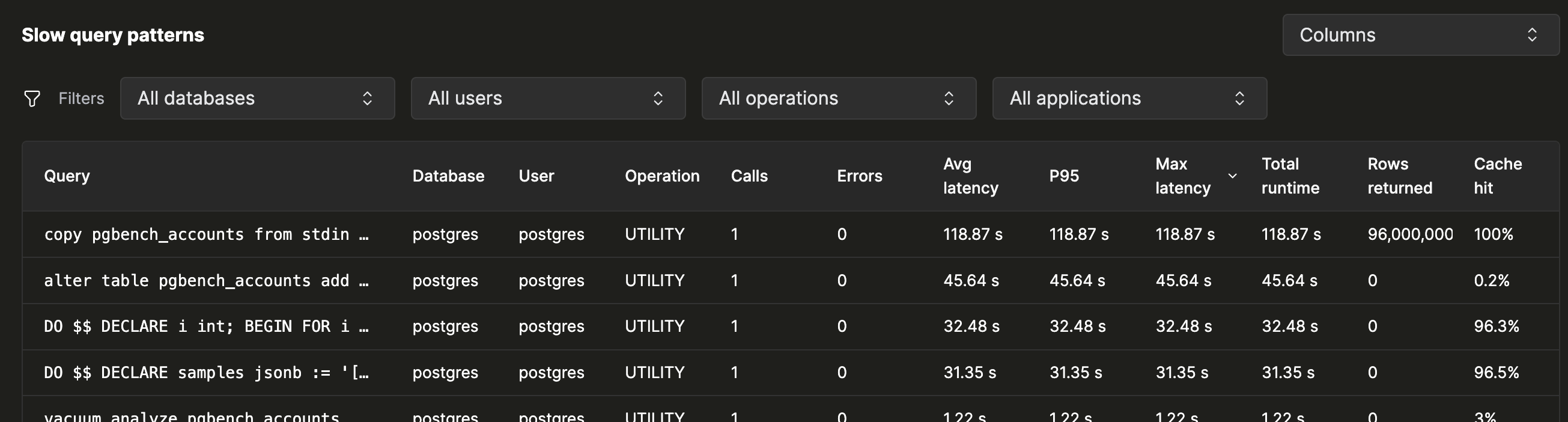
Сортируйте по тому, что кажется подозрительным
По умолчанию таблица отсортирована по Общему времени выполнения по убыванию — при такой сортировке верхний шаблон запроса обычно и отвечает на вопрос: «что обходится мне дороже всего?» При этом сам по себе он не обязательно будет самым медленным. Запрос, который выполняется восемь миллионов раз в день и занимает двенадцать миллисекунд, может значить больше, чем тот, который выполнился один раз за три секунды.
Каждая сортировка дает свой ракурс:
- Общее время выполнения — где база данных потратила больше всего фактического времени.
- Время CPU — вычислительно затратные шаблоны запросов.
- Вызовы — шаблоны запросов с высокой частотой.
- Ошибки — повторяющиеся сбои.
- Средняя / P50 / P95 / P99 / Макс. задержка — выбросы по перцентилям.
- Возвращено строк, Прочитано блоков, Попаданий в блоки, Байты WAL — шаблоны запросов, через которые прошло больше всего данных через движок, кэш или журнал упреждающей записи.
Нажмите кнопку Столбцы, чтобы показать дополнительные столбцы. В таблице шаблонов запросов всего 19 столбцов, включая разбиение по перцентилям, коэффициент попаданий в кэш и время CPU для каждого шаблона запроса.
Сузьте таблицу
Отфильтруйте таблицу так, чтобы видеть только тот срез вашей рабочей нагрузки, который вы анализируете:
- База данных
- Пользователь
- Операция (
SELECT,INSERT,UPDATE,DELETE, …) - Приложение —
application_nameиз строки подключения
«Покажите только то, что делает сервис orders в БД sales»
превращается в два выпадающих списка. Значения фильтров заполняются
автоматически на основе того, что фактически выполнялось на вашем
экземпляре.
Недавние запросы
Под таблицей шаблонов панель Recent Queries показывает отдельные выполнения в обратном хронологическом порядке — одна строка на каждый выполненный оператор, а не одна строка на шаблон. Используйте её, когда нужен поток сырых событий, а не агрегированные данные, например чтобы убедиться, что исправление применилось, или найти точный момент возникновения ошибки.
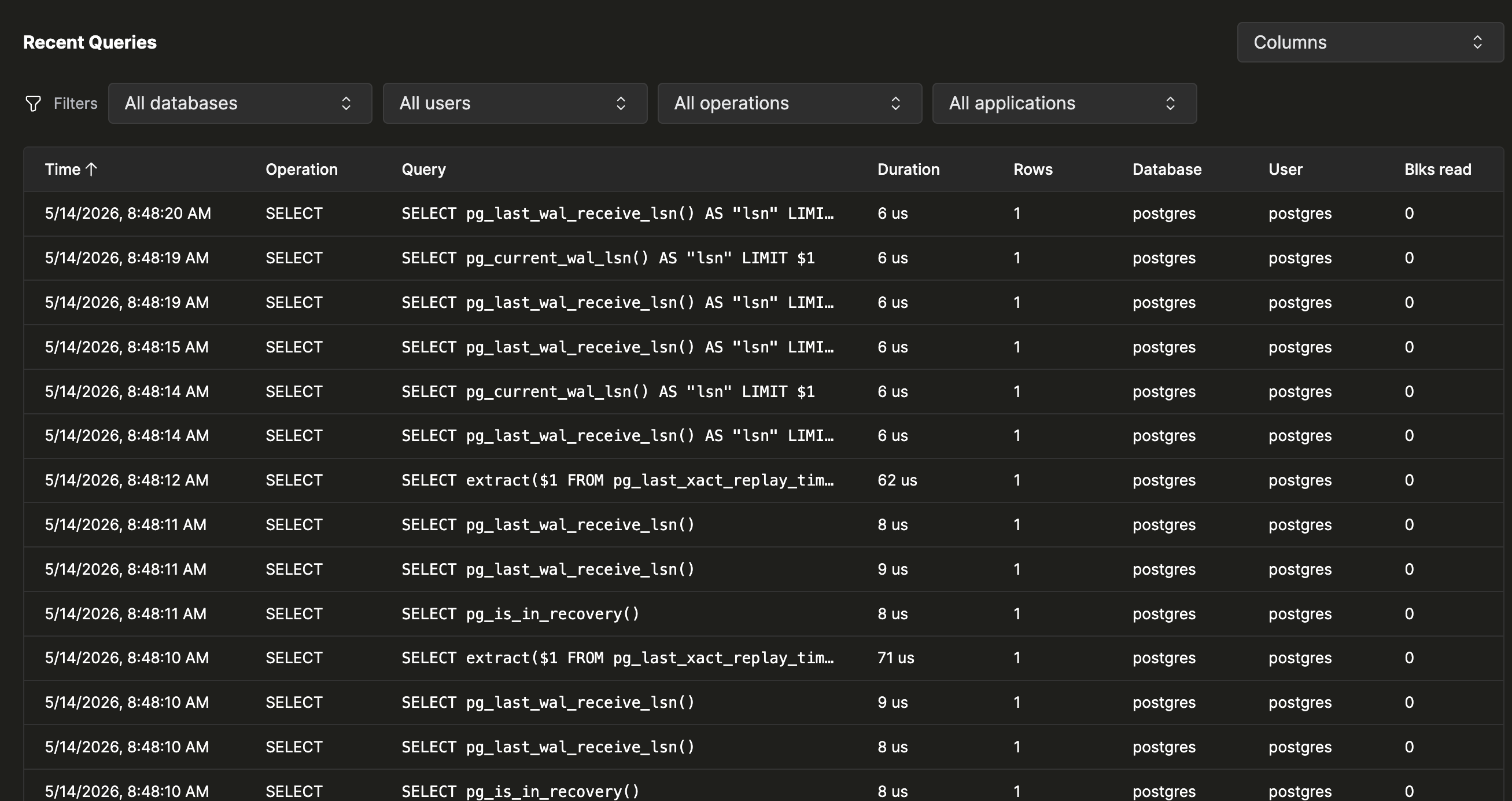
По умолчанию отображаются столбцы Time, Operation, Query, Duration, Rows, Database, User и Blks read. Откройте селектор Columns, чтобы добавить Application, Blks hit, CPU user, CPU sys и PID. Таблица поддерживает те же фильтры Database, User, Operation и Application, что и таблица шаблонов, и сортировку по Time, Duration, Rows, Blks read и CPU time.
Щёлкните любую строку, чтобы открыть ту же выдвижную панель сведений, что и в таблице шаблонов, но только для шаблона этого конкретного выполнения.
Выдвижная панель сведений
Нажмите любую строку в таблице шаблонов или недавних запросов, и справа откроется выдвижная панель Сведения о запросе. Панель собирает все выполнения этого шаблона за выбранный диапазон времени и агрегирует показатели, которые помогают понять, почему он работает медленно.
Панель состоит из единого прокручиваемого макета с пятью разделами:
- Шаблон запроса — нормализованный SQL, в котором литералы заменены на
$1,$2, …, и кнопка копирования в буфер обмена. - Агрегированное использование ресурсов — сетка из 13 карточек со статистикой: общее число вызовов, средняя/P95/P99/макс. задержка, общее время выполнения, число возвращённых строк, коэффициент попаданий в кэш, считанные блоки, блоки с попаданием, время CPU, байты WAL и ошибки.
- Контекст запроса — база данных, пользователь, операция и приложение, из которых поступил этот шаблон.
- Примечательные выполнения — ошибки, необычно медленные запуски и выполнения с большим объёмом результата, показанные перед полным списком недавних.
- Недавние выполнения — отдельные запуски одного и того же шаблона с показателями для каждого выполнения.
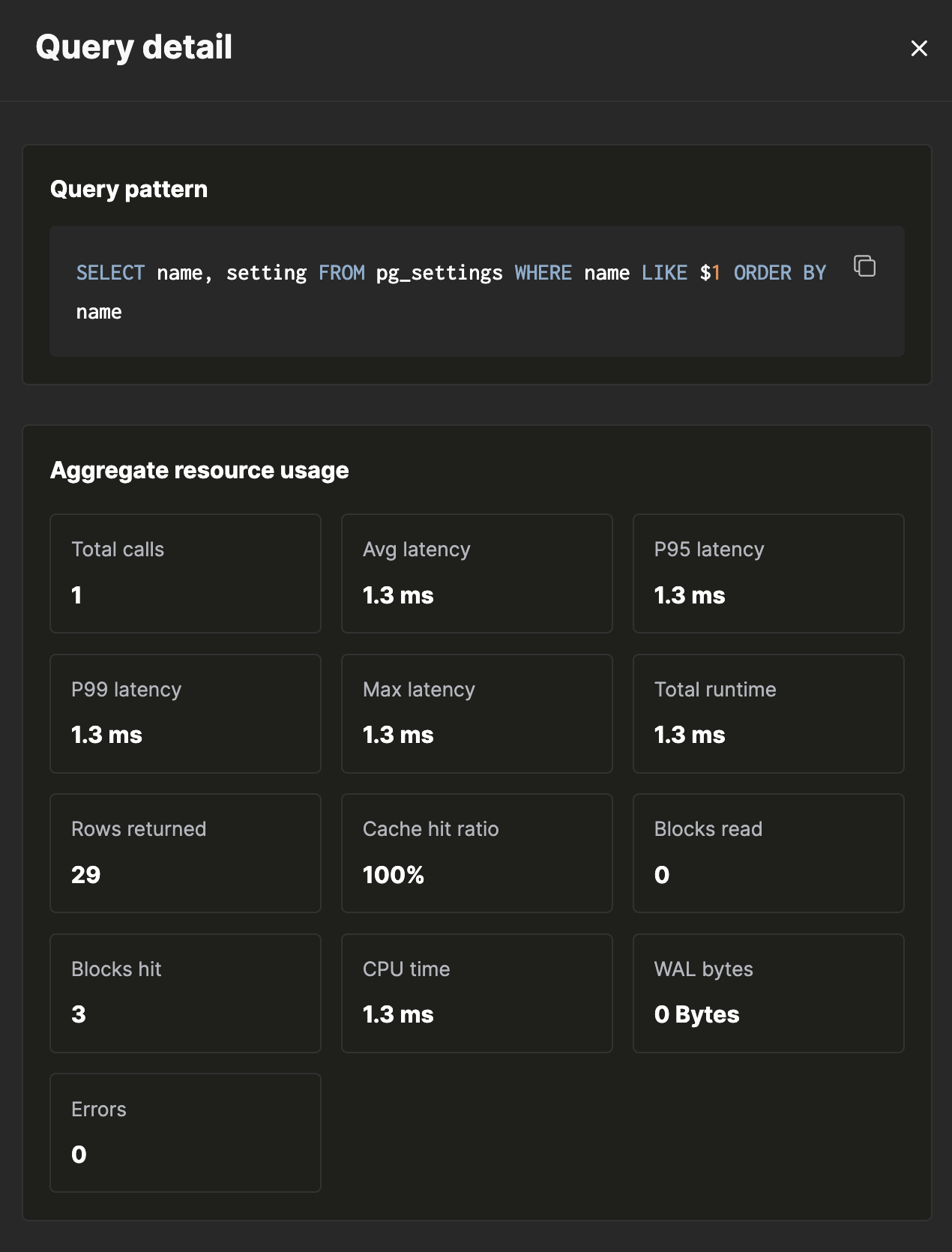
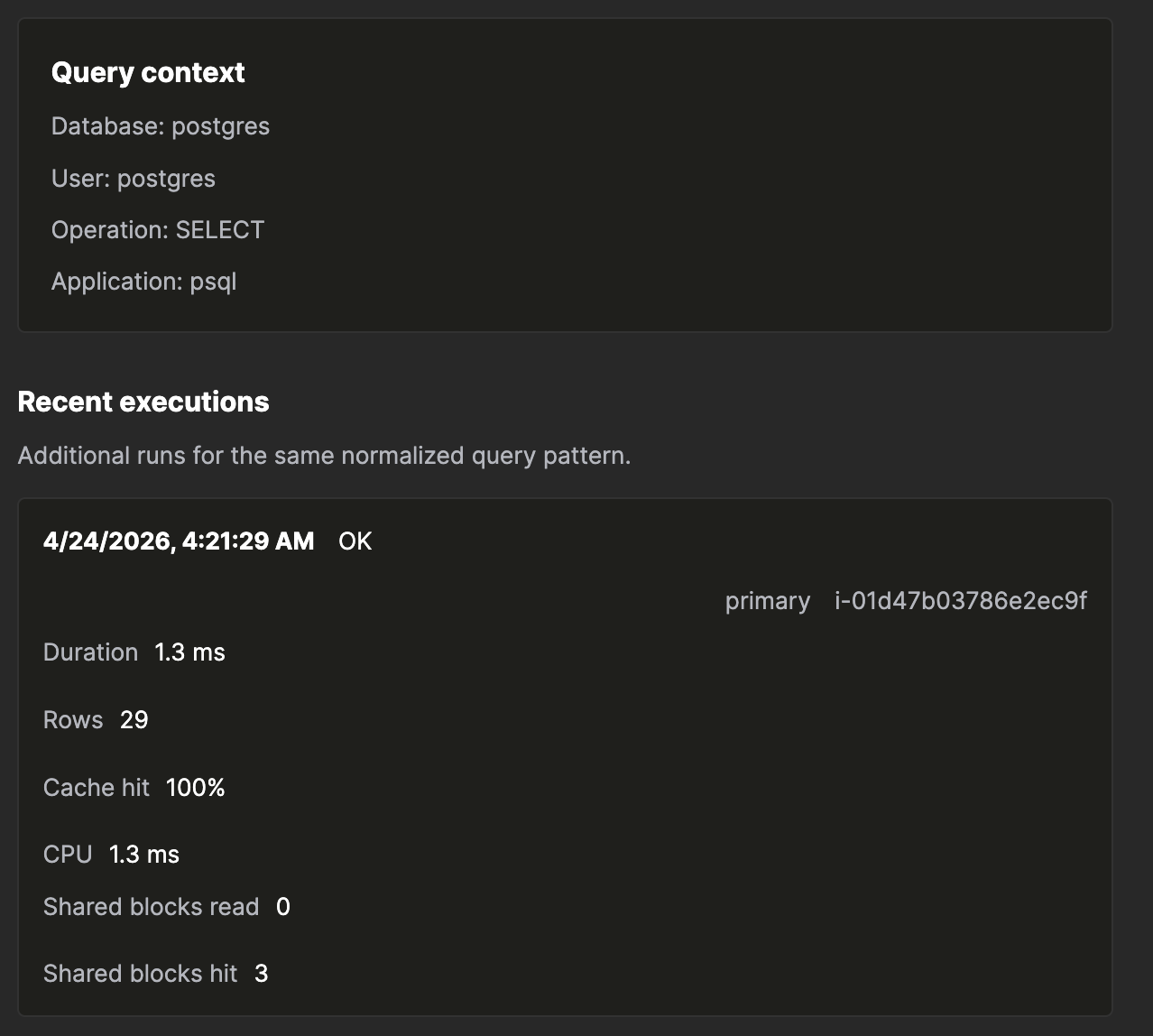
Счётчики для каждого выполнения
Раскройте недавнее выполнение, и вы увидите счётчики, которые точно показывают, куда ушло время:
- Общие блоки — прочитанные и найденные в кэше показываются всегда; записанные и помеченные как dirty показываются, если их значение не равно нулю.
- Операции с локальными и временными блоками — ненулевые операции с временными блоками означают, что сортировка или хеш-операция выгружались на диск.
- Время чтения / записи — время ввода-вывода, отдельно от времени CPU.
- Время CPU — пользовательское и системное, по отдельности.
- Параллельные воркеры — сколько планировалось и сколько было запущено фактически.
- JIT — общее время JIT-компиляции и количество функций.
- WAL — объём в байтах и количество записей.
Всё, что нужно для диагностики медленного шаблона запроса, собрано в одном месте, на одном экране.
Как это работает
Нормализуется в Postgres до отправки по сети
pg_stat_ch перехватывает фазу parse-analyze, заменяет каждый литерал на
плейсхолдер ($1, $2, …) и кэширует получившийся шаблон в
LRU-кэше для каждого backend-соединения с ключом queryid. Когда выполнение
оператора завершается, к событию прикрепляется именно этот кэшированный шаблон. Точный
оператор со значениями никогда не покидает базу данных.
Не мешая работе базы данных
Компонент-производитель добавляет примерно 3 % накладных расходов на каждый оператор. Путь постановки в очередь использует неблокирующий try-lock для кольцевого буфера в общей памяти. При высокой нагрузке расширение отбрасывает события, увеличивая счетчик, вместо того чтобы создавать обратное давление на Postgres.
Необработанные события, а не агрегаты
pg_stat_ch генерирует одно необработанное событие для каждого выполненного оператора (верхнего уровня и
вложенного), если он попал в выборку. Каждый процентиль, ранжирование и разбиение
в интерфейсе — это запрос ClickHouse к тому же потоку событий.
Тот же движок, что используют наши клиенты
В качестве бэкенда Insights используется ClickHouse Cloud. Телеметрия по отдельным запросам из загруженного экземпляра Postgres — это миллионы строк в день; столбцовое сжатие позволяет недорого хранить месяцы детализированных данных по каждому выполнению, а агрегации по миллиардам строк менее чем за секунду позволяют интерфейсу оставаться интерактивным, пока вы анализируете данные за неделю или месяц.
Открытый исходный код
pg_stat_ch распространяется по лицензии Apache 2.0. Запускайте его с любым Postgres и отправляйте данные в любой
ClickHouse. Исходный код и информация о проблемах доступны на
github.com/clickhouse/pg_stat_ch.
Связанные страницы
- Панель мониторинга — встроенные графики ресурсов и активности
- Конечная точка Prometheus — сбор метрик уровня хоста в собственный стек обсервабилити
- Расширения — расширения, доступные в экземплярах Managed Postgres
pg_stat_chна GitHub — расширение с открытым исходным кодом, лежащее в основе Query Insights
